This adventure in maintainable
software is included because some very stringent requirements and a couple of
significant requirements which came in late in the project lead to a highly
maintainable architecture/design. This
was a firmware project for what was called a BootROM in an embedded system. One aspect of this type of application is that
unless you count the system code which is loaded, there is no application data
but some configuration data.
The restrictions
and requirements were roughly as follows:
o
The system buss was VME which is/was the standard
for large embedded systems
o
The RAM available for firmware use was very
limited. There was enough for roughly 3
stack frames as generated by the C compiler which limited the calling depth
o
There was no practical limit on ROM address
space
o
There was a good amount of flash memory for
configuration data
o
It required using three languages (assembler, C
and Fourth)
o
It must support simultaneously an arbitrary
number (0 to n) of Human Interface devices (keyboards, displays, and RS-232
ports. Late in the project was added
remote console (LAN) interfaces. All of
these interfaces were to remain active even while the OS/user system was being
loaded
o
It must be capable of finding an arbitrary
number of bootable systems on each of an arbitrary number of bootable devices (disks
and remote (LAN) servers)
o
It must be capable of accepting input from
keyboards configured for any of dozens of human languages and displaying
messages in those languages.
o
It must be capable of running diagnostics for
any user supplied device which appeared on the VME bus.
o
Late in the project a requirement was given to
support what was known as hard real time.
What this mostly meant was that the system as a whole must be capable of
going from power on to user code running under Linux in under 30 seconds. What
this required of the firmware was to ignore HI devices and to disable all
diagnostic code except for devices directly involved in the boot process
o
Oh! And if possible allow users to modify the
code
The requirement
for Forth came about because at the time there was a push for a way to allow
device interfaces to contain their own driver code. This was to be the way in which interface
testing and boot support was to be supplied so that firmware did not have to be
constantly updated for new or changed devices.
A group of manufactures and suppliers including, Hewlett-Packard and
Apple had come to an agreement that Forth would be the language used to
implement this capability. Also at this
time a IEEE standard for Forth was accepted.
The problem of
supporting keyboards for any language was solved by using a pure menu based human
interface system where menu items were selected by keying a number. This worked because all keyboards have the
same key position for the numbers (excluding number pads).
A breakthrough solution
for the stack depth problem came when I realized that if code was broken up into
small functions that a state-machine could be used to represent calling
sequences and the stack depth could then be limited to a single level. A refinement of this design was to limit the
number of function arguments to three because the C compiler always put the
first three arguments into registers rather than on the calling stack thus
further reducing the stack frame size. The
state machine description could be stored in ROM.
The rough process
used to create such a representation was to translate each subroutine into a
state machine representation by refactoring each straight line code segment (code
between routine calls) into a function and replacing each subroutine/function
call with the state machine representation of that routine. This was rather laborious but fortunately
most routines were small and straight line.
The following is a simple abstract example
of this flattening and state machine representation:
‘Normal version’ for simplicity it is
assumed that only sub2 calls another routine.
subroutine
A(arg1)
code seg1
v1 = func1(arg1)
if (v1=1) call sub2(arg1) else call sub3(v1)
code seg2
call sub4(v2)
end sub
A
subroutine
sub2(argx)
code seg3
call sub5
end sub2
‘State machine version’
Code segments 1, 2, 3 etc. are
refactored as functions. Most often the
return value is a 0 or 1 indicating success or failure.
Rv is the return value while Arg1 and V1
are a ‘global’ variables
StateA1
Rv=seg1();
stateA2
StateA2
Rv=func1(Arg1) ; 1,stateS2.0; 0,stateA3
StateA3
Rv=Sub3(V1); 1,stateA4
StateA4
Rv=seg2(); 1,stateA4
StateA5
Rv=Sub5(); 0
The 0 or
here indicates completion for the machine
State
S2.0 // this implements sub2
Rv=seg3(); state S2.1
State
S2.1
Rv=Sub4(); stateA4 // this is the return
from sub2
Another
innovation was in the state-machine representation and its ‘interpreter’. In conventional state-machines, the
‘interpreter’ operates by calling a routine which returns an value (often a
character from an input source) this value along with the number of the current
state is used to index into a two dimensional array to fetch the number of the
next current state, this number is also used to select and call a routine which
is the action associated with the state.
This process is repeated until some final state is reached.
The main problem with
this design is that as the number of states increases the number of empty or
can’t get there values in the state table increases along with the difficulty
in understanding what the machine is doing.
Documentation can help but must be changed every time the state machine is
changed. The solution I came up with was
to represent the state-machine as a table of constants in assembler language
and use addresses instead of index numbers.
Each state has a name and contains the address of the function to call,
its arguments and a list of value-next state pairs. The following examples and explanations may
be a bit tedious for some people but they form the basis for my solution to the
multiple HI devices problem as well as solving the stack size problem.
In this example
the dc stands for Define Constant and the -* causes a self-relative address to
be produced, this will be explained later
stateX1 dc ‘op1 ‘ //arg1
dc
1 //arg2
dc 0 //arg3 not used
dc
myfunc-*
dc
value1,stateX1-* // repeat stateX1
dc
value2,stateX2-*
dc 0,0 // end of list
The calling a
routine for an input value was eliminated and the ‘interpreter’ ran by using
the current state address to select the function to call but then used the
return value from that call to select the next state from a list tailored to
that functions return values. This
minimizes the amount of space to represent the state machine and makes it somewhat
easier to follow a sequence of transitions.
The requirement to
support simultaneous use of multiple HI devices even while the OS/system is being
loaded provided a significant challenge because there was not enough available
RAM as well as other issues which prevented using an interrupt based mechanism
like the Operating Systems do. Firmware
had to use a polling mechanism which meant that the user ‘lost control’ while
the OS was being loaded as well as at other times. The requirement to support a LAN based
console was over the top because driver code in general had never been
implemented or even designed to be used for two different purposes at the same
time.
The multiple
simultaneous HI device ‘problem’ was solved primarily by changing the state
machine to support a cooperative multi-threading mechanism and then creating a
thread for each input device and a separate thread for the selected boot device. Each input device thread was a two state
state-machine which called the driver requesting a character. If one was not found, the next state is the
same as the current state and when one was read, the next state called a
function which invoked the menu system then transitioned to the first state.
This worked
because the state-machine interpreter was modified to work with a list of state
machine records. I do not remember the
details of how it was implemented but even now I can think of at least three
ways it could have been done. The essence
is that the interpreter would pop the next state address off a list and execute
the state selected. After executing the
state, new next state address was put on the end of the list and the cycle
would be repeated. The effect of this was to switch threads on state boundaries
and therefore after each function call.
The LAN driver was converted to state-machine format and refactored to
have both boot protocol and console protocol components thus allowing the
console and boot operations to work simultaneously.
At the time of this
design, there was great interest in using ‘building blocks’ as a way to
construct easy to build and maintain systems.
No one had as yet actually tried or even come up with a concrete
proposal. Because we anticipated a huge
maintenance work load after the first system release I decided to try to come
up with something for this project.
The
resulting architecture initially consisted of a ‘core’ block an English
language block, a set of driver blocks and an end block.
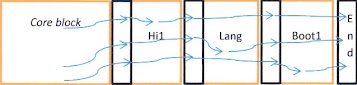
The Core block
contained normal BootROM stuff, including basic initialization, the Forth
Interpreter and various general utility routines which could be used by all
blocks. The End block was nothing more
than a set of null pointers to terminate all the lists. There were in fact several more linked lists
than are shown in the above diagram. All
of these links were self-relative pointers and were paired with a bit pattern
which indicated if there was anything of interest at that address for example
text for English or code for a human input device. Each block relied on the assumption that
there would be a set of pointers immediately following its own code. Each block was compiler/assembled
independent of one another. The ‘ROM’ was constructed by extracting the code
from compiled files and literally concatenating them between the Core block and
the End block. This architecture
required code and addresses such as the ones in the state-machine tables and
the lists running thru the blocks to be self-relocating. The compiler generated self-relocating
code. The self-relocating requirement
for addresses was met by making them self-relative (add the value at an address
to its address to produce the required needed address. The null pointer was detected
by checking for zero before the addition step.
The ‘multiple
human languages’ requirement was met in part by the HI input device mechanism
described above and in part by using a pure menu system and in part by the following
mechanism.
All of the text
for all human visible messages was placed in a table and referred to by a
number. This text consisted of phrases
and single words which could be combined as needed. Messages as stored in the
table could be either text or a string of message numbers. When a message needed to be displayed, a call
would be made to a print routine in the Core block and giving it the message
number. This routine would find the
language table for the currently configured language, construct the text version of the message then
find all the console output devices and have them display the message.
These messages
and message fragments were developed by Human Factors specialists. I developed a simple emulator (in Perl) which
would behave like the ROM in terms of how the menu system worked and how it
would react to error conditions. These
specialists then had complete control over the message text. This allowed parallel development of code and
user manuals. When the time came to
deliver the ROM, I used a Perl script to
extract the messages and generate the English language block. The same or very similar process was used to
generate the French language block.
The last requirement
(“Oh! And if possible allow users to modify the code”) was put in place by
creating a developer’s kit which consisted of a lot of documentation, the ready
to concatenate files used in the ‘standard’ ROM and the scripts used to create
them.
Historical notes:
o
Shortly after the first release of this ROM,
Apple came out with the first device which was to support the Forth language
concept. Instead of Forth, their ROM
contained machine code. Their comment
was ‘we never intended to support Forth’.
That killed the initiative.
o
The system this ROM was part of was designed to
work in hostile/demanding environments primarily for data collection/management
purposes. As I recall, it was used in
monitoring tracks for the Japanese bullet trains, doing something in the latest
French tanks, monitoring and controlling sewage treatment plants, collecting
and displaying data for an Air Traffic control system and collecting and
displaying data in the US Navy Aegis weapon systems.
o
I did train engineers for one company to allow
them to build their own ROMs.
o
About a year after releasing this project, the
division was disbanded but maintenance was transferred to another
division. About five years after this I
talked with an engineer who had been assigned to maintaining the ROM and he
said that he had been maintaining it by himself for a few years and had
released new modules and had easily made several releases per year by himself.
Summary of things done and
learned:
o
Used Assembler, Forth and C in the same
application.
o
Designed and implemented what may be the only
true ‘building block’ system.
o
Learned that separating control logic from
computational logic helps maintainability.
o
State-machines are a viable way to keep control
and computational logic separate and make the control logic very visible.
o
Simple emulators can be used to see what an
application will look and behave like before and while the application is being
built. They can be cost effective
because the allow scenario testing before the code becomes too rigid.
o
Learned a lot about multi-threaded systems work
in a very controlled environment
o
The building block architecture proved to be a
very good way to improve maintainability

{kind=link}
{kind=link}